Planner Matters! An Efficient and Unbalanced Multi-agent Collaboration Framework for Long-horizon Planning
Framework Overview
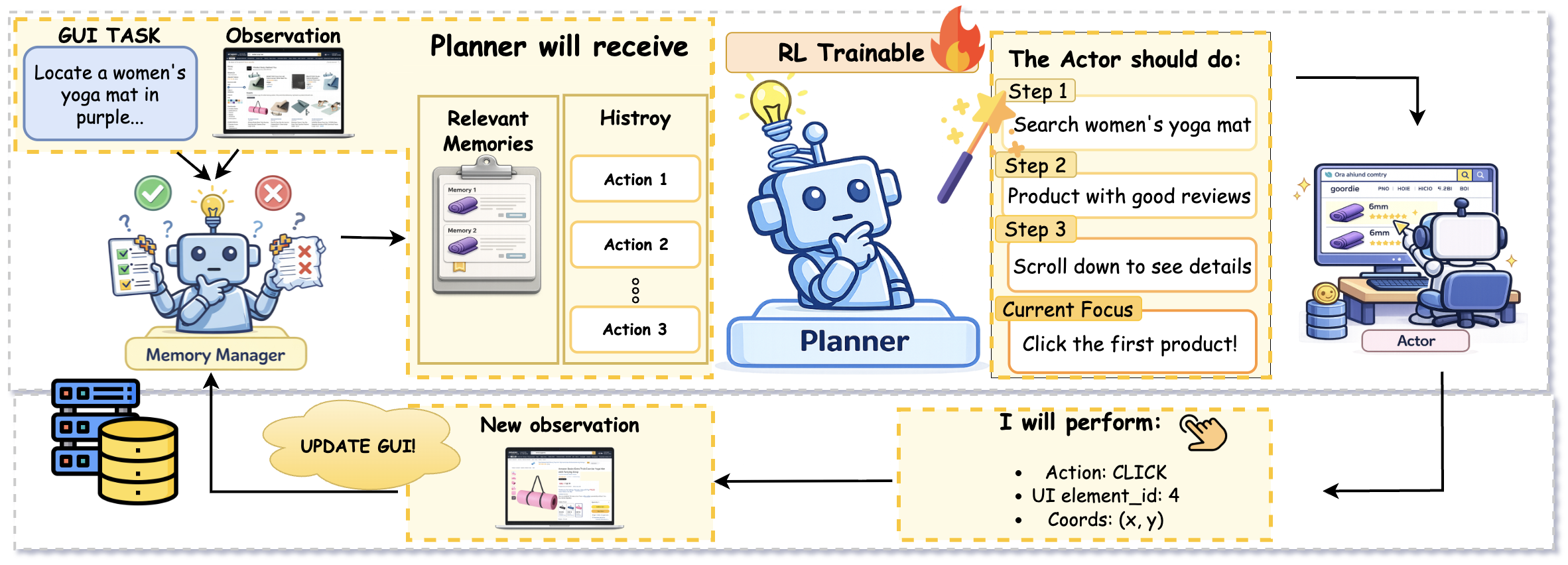
Multi-agent Framework: We decompose GUI automation into Planner (high-level step-by-step planning), Actor (low-level execution: click, type, scroll, etc.), and Memory manager (retrieval and use of past experience). Planning is the dominant factor—we introduce planner-centric RL that optimizes only the planner with trajectory-level rewards from a VLM-as-judge, while keeping actor and memory frozen.
Abstract
Language model (LM)–based agents have demonstrated promising capabilities in automating complex tasks from natural language instructions, yet they continue to struggle with long-horizon planning and reasoning.. We address this challenge by proposing a human-like multi-agent framework that decomposes automation into a planner, an actor, and a memory manager, enabling structured decision-making across extended interaction horizons. Empirical results show that this decomposition substantially improves performance on complex GUI tasks, and is also effective in other scenarios like tool-use. Viewing the system through a compute-allocation lens, we further analyze the necessity of model capacity across agent roles and find that planning is the dominant factor, while execution and memory can be handled by significantly smaller models with minimal performance loss. Motivated by this observation, we introduce a planner-centric reinforcement learning approach that exclusively optimizes the planner using trajectory-level rewards from a VLM-as-judge, while keeping other agents frozen. Extensive experiments demonstrate that concentrating model capacity and learning on high-level planning yields robust and compute-efficient improvements in long-horizon agent automation. Our code is publicly released.
Case Studies
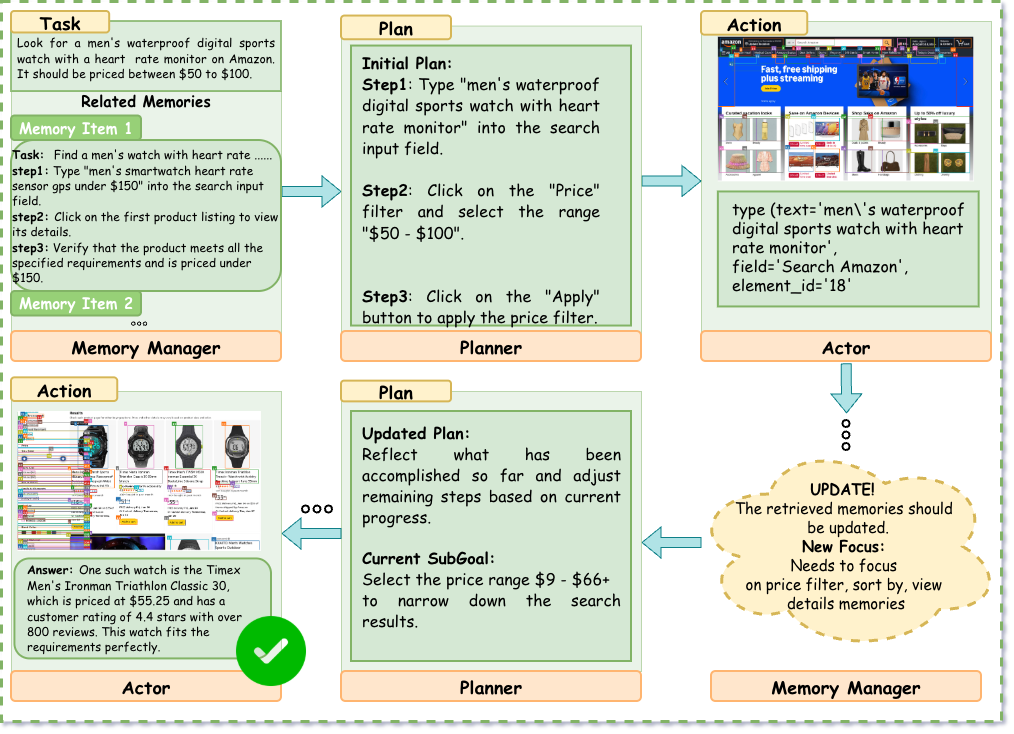
Amazon — Planner-Centric Multi-Agent (Success)
In contrast, our framework demonstrates structured reasoning.
- Decomposition: The Planner initially decomposes the user query into a search action followed by a refinement phase.
- Dynamic Adjustment: After the Actor executes the initial search, the Planner analyzes the observation. Recognizing that the results are mixed, it updates the plan to explicitly target the "Price" filter.
- Precise Execution: The Planner issues a subgoal to "Select the price range $50 - $100". The Actor, relieved of the burden of long-horizon planning, focuses solely on locating and clicking the correct element ID (element_id: 45).
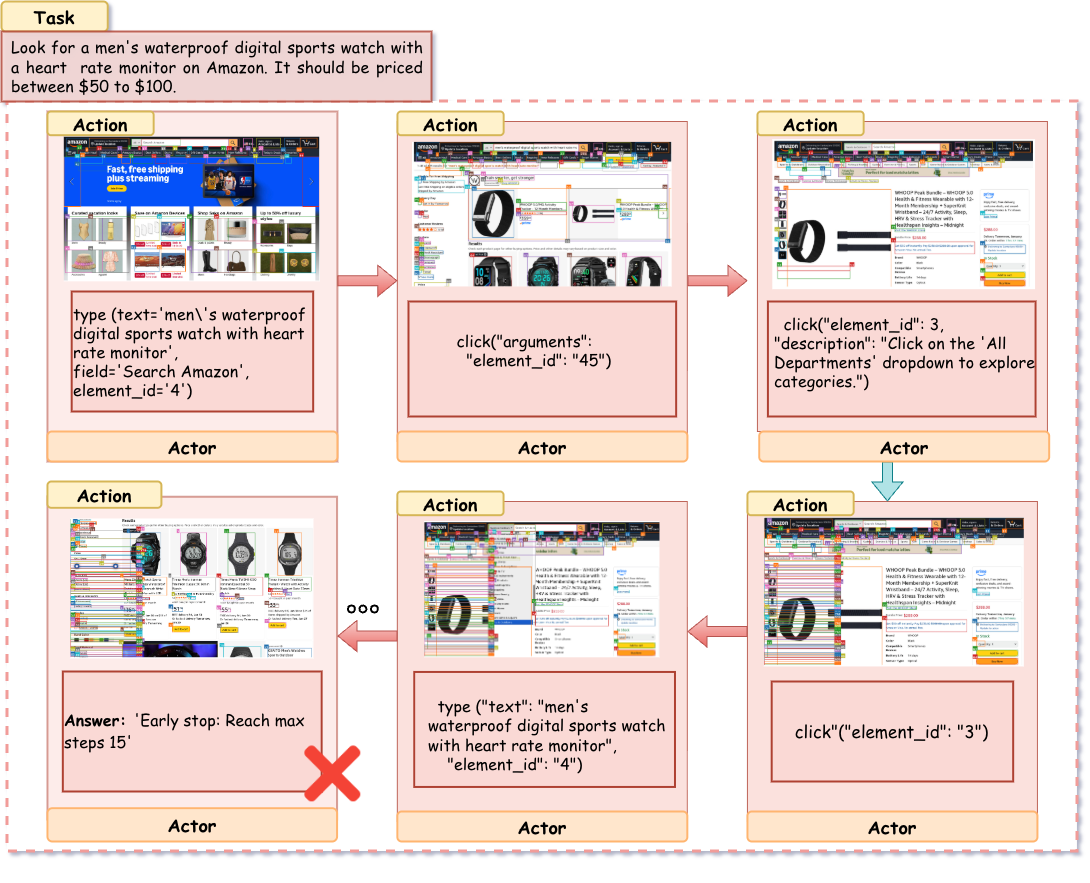
Amazon — Single-Agent Baseline (Failure)
The monolithic agent attempts to solve the task by relying solely on search queries. It types the full query into the search bar but fails to leverage the sidebar filters to narrow down the results. Faced with a noisy results page containing items outside the $50–$100 range, the agent struggles to verify the price constraint visually. It enters a repetitive loop of scrolling and viewing irrelevant details, ultimately terminating due to the maximum step limit (Step 15) without locating a valid product. This highlights the difficulty monolithic models face in balancing high-level constraint satisfaction with low-level interaction.
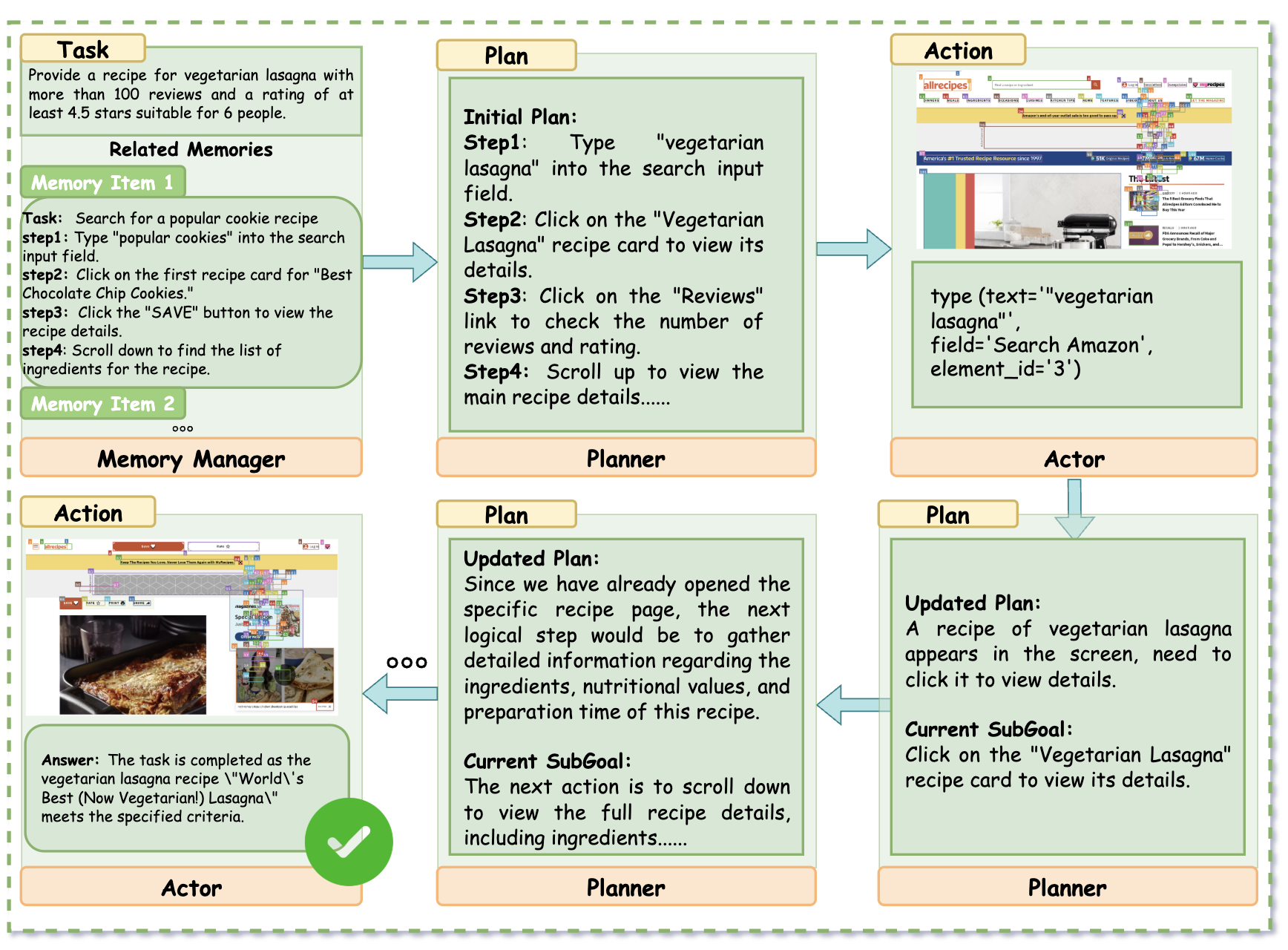
Allrecipes — Multi-Agent Framework (Success)
Task: "Find a vegetarian lasagna recipe with 100+ reviews, 4.5+ rating, and suitable for 6 people."
The Planner decomposes the task into subgoals—searching, checking reviews, and extracting full recipe details. The Actor executes these steps accurately, leading to successful retrieval of a valid recipe.
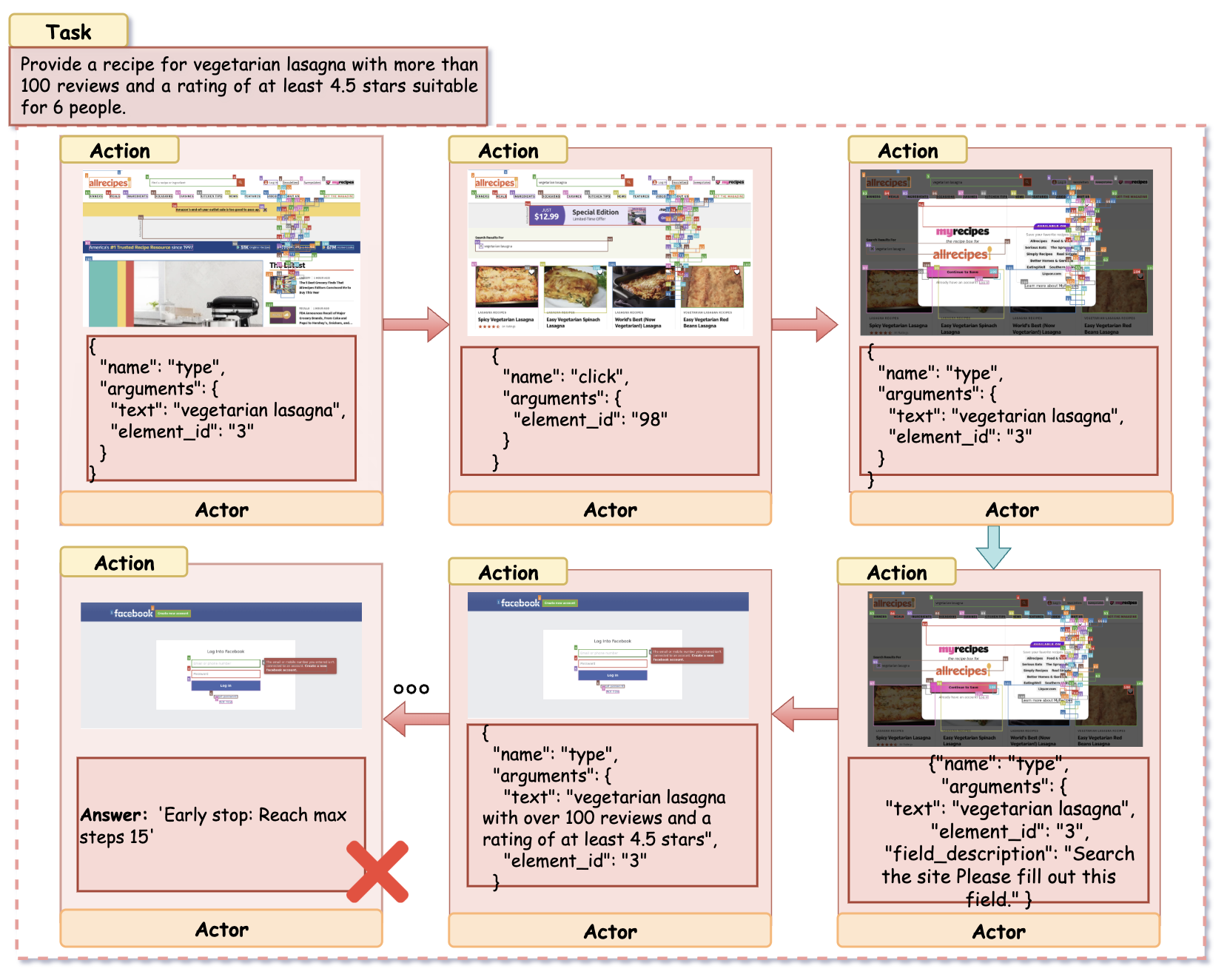
Allrecipes — Single-Agent Baseline (Failure)
The agent repeats search queries but fails to verify constraints or navigate to the correct page. It loops through irrelevant results and reaches the step limit without success. This highlights how structured planning and role separation improve constraint satisfaction and task efficiency.
Performance comparison Leaderboard
Task success rates (%) across WebVoyager, Mind2Web, and MMInA. Bold indicates best-performing open-source models in each domain. OOD denotes the Out Of Domain setting. Overall is averaged across available domains.
| Backbone | Model/Method | WebVoyager (In Domain) | Mind2Web & MMInA (OOD) | Avg. | Δ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Amz | Cour | Recp | Map | Info | Svc | Ent | Trav | Wiki | ||||
| Closed-Source | ||||||||||||
| GPT-4o | 24.4% | 7.1% | 13.3% | 36.6% | 7.8% | 14.1% | 3.4% | 19.4% | 51.0% | 19.7% | ||
| Gemini-Pro-Vision | 41.7% | 28.6% | 20.0% | 53.7% | 16.7% | 22.4% | 0.0% | 19.4% | 50.0% | 29.6% | ||
| Claude-4 | 63.4% | 28.6% | 33.3% | 70.0% | 25.6% | 40.0% | 6.9% | 9.7% | 52.0% | 36.6% | ||
| Open-Source | ||||||||||||
| Qwen2.5-VL-32B | 46.3% | 26.2% | 6.7% | 29.3% | 14.1% | 20.0% | 6.9% | 9.7% | 43.0% | 22.5% | ||
| CogAgent | 12.2% | 9.5% | 26.7% | 9.8% | 24.4% | 8.2% | 13.8% | 16.1% | 21.0% | 15.7% | ||
| Websight | 24.4% | 4.8% | 13.3% | 29.3% | 10.3% | 3.5% | 3.4% | 0.0% | 12.0% | 11.2% | ||
| UI-TARS-1.5-7B | 31.7% | 16.7% | 20.0% | 31.7% | 6.4% | 4.7% | 6.9% | 0.0% | 36.0% | 17.1% | ||
| Qwen2.5-VL-3B | Baseline | 7.3% | 11.9% | 8.9% | 4.9% | 12.8% | 4.7% | 6.9% | 6.5% | 7.0% | 7.9% | — |
| + Base RL | 31.7% | 33.3% | 20.0% | 29.3% | 19.2% | 16.5% | 10.3% | 6.5% | 23.0% | 21.1% | +13.2 | |
| + Multi-Agent | 22.0% | 14.3% | 4.4% | 14.6% | 15.4% | 5.9% | 13.8% | 6.5% | 15.0% | 12.4% | +4.5 | |
| + Multi-Agent RL | 31.7% | 33.3% | 24.4% | 41.5% | 21.8% | 17.6% | 13.8% | 12.9% | 23.0% | 24.0% | +16.1 | |
| Qwen2.5-VL-7B | Baseline | 14.6% | 2.4% | 15.9% | 16.7% | 9.0% | 11.8% | 0.0% | 4.4% | 38.0% | 12.5% | — |
| + Reasoning Bank | 29.3% | 9.5% | 6.7% | 29.3% | 9.0% | 20.0% | 3.4% | 6.5% | 44.0% | 17.5% | +5.0 | |
| + AWM | 17.1% | 4.8% | 11.1% | 29.3% | 7.7% | 10.6% | 0.0% | 6.5% | 31.0% | 13.1% | +0.6 | |
| + CoMEM | 24.4% | 17.1% | 8.9% | 34.1% | 16.7% | 23.5% | 10.3% | 12.9% | 47.0% | 21.7% | +9.2 | |
| + Base RL | 46.3% | 21.4% | 24.4% | 48.8% | 23.1% | 23.5% | 6.9% | 6.5% | 34.0% | 26.1% | +13.6 | |
| + Multi-Agent | 56.1% | 33.3% | 24.4% | 48.8% | 15.4% | 21.2% | 3.4% | 3.2% | 41.0% | 27.4% | +14.9 | |
| + Multi-Agent RL | 68.3% | 38.1% | 33.3% | 63.4% | 21.8% | 23.5% | 10.3% | 12.9% | 44.0% | 35.1% | +22.6 | |
| Qwen3-VL-8B | Baseline | 36.6% | 16.7% | 13.3% | 43.9% | 9.0% | 20.0% | 10.3% | 9.7% | 38.0% | 21.9% | — |
| + Reasoning Bank | 36.6% | 11.9% | 17.8% | 31.7% | 10.3% | 24.7% | 17.2% | 6.5% | 48.0% | 22.7% | +0.8 | |
| + AWM | 39.0% | 19.0% | 8.9% | 31.7% | 12.5% | 16.5% | 6.9% | 16.1% | 48.0% | 22.1% | +0.2 | |
| + Continuous | 43.9% | 19.0% | 17.8% | 34.1% | 12.5% | 17.9% | 3.4% | 19.4% | 42.0% | 23.3% | +1.4 | |
| + Base RL | 46.3% | 38.1% | 33.3% | 48.8% | 25.6% | 18.8% | 10.3% | 6.5% | 45.0% | 30.3% | +8.4 | |
| + Multi-Agent | 56.1% | 33.3% | 28.9% | 58.5% | 21.8% | 27.1% | 20.7% | 16.1% | 54.0% | 35.2% | +13.3 | |
| + Multi-Agent RL | 63.4% | 42.9% | 37.8% | 53.7% | 26.9% | 23.5% | 17.2% | 9.7% | 51.0% | 35.8% | +13.9 | |
Performance Comparison on OSWorld across different methods.
| Method | Office | Daily | Professional | Others | Overall | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Writer | Calc | Impress | Avg. | thunder. | vlc | chrome | Avg. | gimp | VsCode | Avg. | M-Apps | OS | ||
| Qwen2.5-VL-7B | 4.3% | 2.1% | 2.1% | 2.6% | 0.0% | 5.9% | 11.1% | 7.8% | 0.0% | 0.0% | 0.0% | 2.0% | 12.5% | 3.9% |
| +Reasoning Bank | 8.7% | 2.1% | 2.1% | 3.4% | 13.3% | 0.0% | 6.5% | 6.4% | 11.5% | 4.6% | 8.3% | 0.9% | 12.5% | 4.7% |
| +Multi-Agent | 8.7% | 0.0% | 4.3% | 3.4% | 13.3% | 0.0% | 8.7% | 7.9% | 11.5% | 0.0% | 6.3% | 3.1% | 12.5% | 5.3% |
| Qwen3-VL-8B | 27.3% | 4.3% | 19.0% | 14.6% | 40.0% | 17.7% | 28.3% | 28.2% | 30.8% | 18.2% | 25.0% | 7.4% | 29.2% | 18.1% |
| +Reasoning Bank | 18.2% | 8.5% | 10.6% | 11.2% | 53.3% | 23.5% | 26.1% | 30.8% | 36.0% | 27.3% | 31.9% | 6.3% | 41.7% | 19.0% |
| +Multi-Agent | 27.3% | 8.7% | 10.4% | 13.0% | 46.7% | 29.4% | 34.8% | 35.9% | 46.2% | 22.7% | 35.4% | 9.6% | 41.7% | 22.1% |
Performance Comparison on MCPBench across different methods.
| Model | Task Completion | Tool Usage | Planning Effectiveness | Execution Fidelity | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Task Fulfill. | Info Ground. | Tool Appropri. | Parameter Accuracy | Dependency Awareness | Parallelism Efficiency | Schema Compliance | Valid Tool Name Rate | Execution Success | Failure Rate | |
| Qwen2.5-7B | 4.72 | 4.54 | 4.46 | 4.42 | 4.08 | 3.73 | 0.57 | 0.57 | 0.52 | 0.05 |
| +Reasoning Bank | 6.09 | 5.84 | 5.50 | 5.67 | 5.71 | 4.70 | 0.81 | 0.74 | 0.68 | 0.10 |
| +Multi-Agent | 6.78 | 6.68 | 6.70 | 6.51 | 5.83 | 5.26 | 0.89 | 0.92 | 0.91 | 0.01 |
| +Multi-Agent+Memory | 6.82 | 6.69 | 5.86 | 6.20 | 5.23 | 4.85 | 0.80 | 0.74 | 0.70 | 0.04 |
| Qwen3-8B | 5.67 | 5.68 | 5.69 | 5.63 | 5.69 | 5.42 | 0.72 | 0.71 | 0.70 | 0.01 |
| +Reasoning Bank | 6.93 | 7.04 | 6.96 | 6.84 | 6.79 | 6.57 | 0.90 | 0.85 | 0.81 | 0.05 |
| +Multi-Agent | 8.71 | 8.59 | 8.57 | 8.60 | 8.22 | 8.09 | 1.00 | 1.00 | 1.00 | 0.00 |
| +Multi-Agent+Memory | 8.10 | 8.26 | 8.29 | 8.15 | 8.26 | 7.51 | 1.00 | 1.00 | 1.00 | 0.00 |
Benchmark Results: Our planner-centric multi-agent framework consistently outperforms baseline approaches across WebVoyager, Mind2Web, and MMInA. Multi-Agent RL (highlighted) achieves the best open-source performance within each backbone.
Scaling Analysis: The Planner Matters Most.
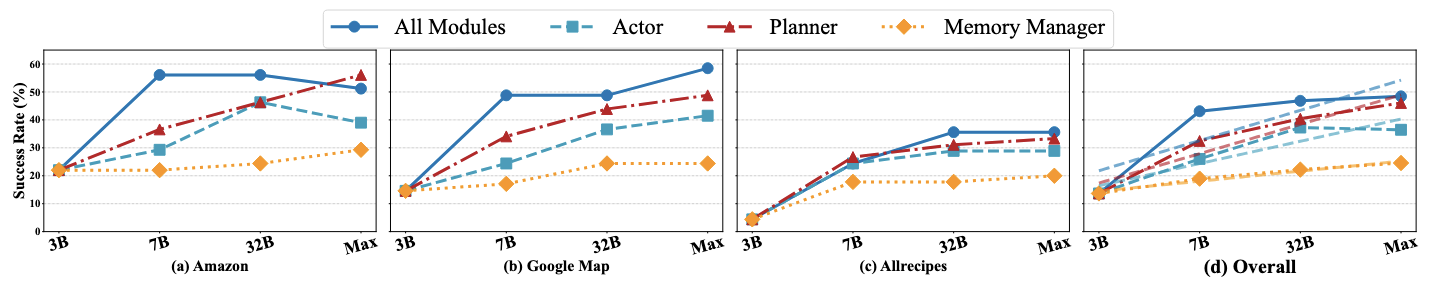
To better understand where model capacity should be allocated within our multi-agent system, we conduct an ablation study that selectively scales one component at a time—Planner, Actor, or Memory Manager—while keeping others fixed. We evaluate performance on three domains, Amazon, Google Maps, and Allrecipes, across multiple backbone models with different sizes, Qwen 3B/7B/32B and Gemini-2.5Pro.
As shown in the figure, scaling the Planner yields significantly greater performance gains than scaling other agents, with diminishing gaps when scaling all modules. This trend holds across models and domains, confirming that the Planner—responsible for high-level reasoning and global control—is the most impactful component. While scaling all modules brings some additional improvement, most gains are achieved by focusing on the Planner. Similar to how the human brain allocates most energy to cognitive functions (Raichle & Gusnard, 2002), prioritizing Planner capacity proves to be an efficient and effective strategy.
Checkpoints and Trajectory Dataset
We provide the following on Hugging Face for reproducibility:
Planner / Agent Checkpoints
Trajectory Dataset (Experience Memory)
BibTeX
@article{planner-matters-2025,
title = {Planner Matters! An Efficient and Unbalanced Multi-agent Collaboration Framework for Long-horizon GUI Planning},
author = {Wenyi Wu* and Sibo Zhu* and Kun Zhou† and Biwei Huang},
journal = {...},
year = {2025}
}